AN IMAGE IS WORTH 16X16 WORDS
1. Objectives of the Paper
What problem is the paper tackling?
The paper addresses the challenge of applying Transformer architecture to Computer Vision tasks, aiming to reduce the heavy reliance on Convolutional Neural Networks (CNNs) in the field. It argues that this transition would yield comparable results to traditional CNNs while requiring fewer computational resources for training.
What is the relevant background for this problem?
Transformers have been extensively used for Natural Language Processing (NLP) tasks, exemplified by state-of-the-art models like BERT and GPT. While there has been some exploration of using transformers for image tasks, it has generally been resource-intensive.
2. Paper Contributions
What methods did the paper propose to address the problem?
The Vision Transformer (ViT) revolutionizes image processing by converting images into a sequence of flattened 2D patches, to which a learnable embedding token is added. This token functions similarly to the class token in BERT, while positional embeddings are added to retain spatial information. The transformer encoder is employed to process these sequences, with alternating layers of multi-head self-attention and MLP blocks. During pre-training and fine-tuning, a classification MLP head is attached to the encoder output. The model is pre-trained on large datasets and then fine-tuned for specific tasks by replacing the pre-trained prediction head with a newly initialized zero-initialized layer.
How are the paper’s contributions different from previous related works?
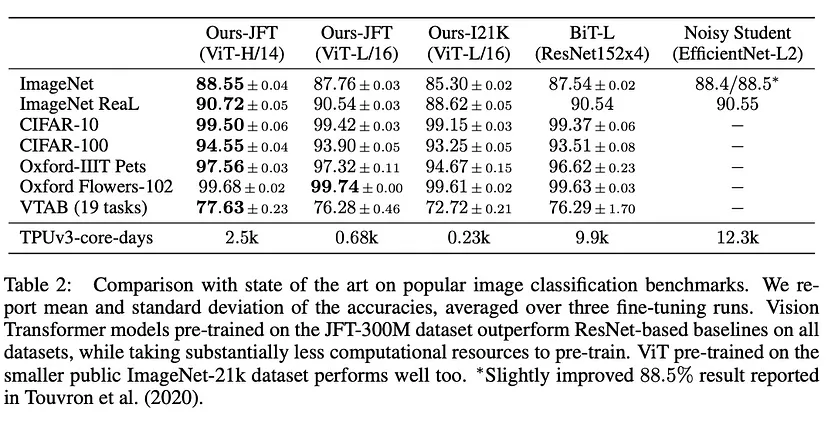
The Vision Transformer (ViT) stands out as one of the first successful applications of standalone transformers for computer vision. Unlike previous models like DETR that used transformers in conjunction with CNNs, ViT operates independently. Its main advantage lies in its ability to achieve similar accuracy to previous models like Noisy Student, but requiring approximately five times less training time. In summary, ViT offers comparable accuracy with significantly reduced computation time, making it a more efficient option for computer vision tasks.
The Vision Transformer (ViT) represents a departure from traditional convolutional neural network (CNN) models by omitting convolutions. While Multilayer Perceptrons (MLPs) theoretically offer superior performance, their practical efficacy has been limited by data constraints. However, ViT overcomes this hurdle by leveraging a large dataset, eliminating the need for the inductive bias inherent in CNNs. Unlike traditional MLPs, transformers employ self-attention as their core mechanism, allowing them to understand input relationships. In Natural Language Processing (NLP), transformers compute bidirectional relations between words, resulting in less strict ordering compared to unidirectional Recurrent Neural Networks (RNNs).
The paper evaluates the effectiveness of the Vision Transformer (ViT) by examining its internal representations through attention heads analysis. It finds that ViT encodes spatial relations between patches and integrates global information even in lower layers. Quantitative performance analysis and qualitative visualization of attention maps further supplement the study.
3. Paper Limitations, Further Research
The paper introduces Vision Transformers (ViT) as an alternative to CNNs or hybrid approaches for image tasks. While the results are promising, they lack performance evaluation for tasks beyond classification, such as detection and segmentation. Unlike previous studies, the performance improvement for transformers is more limited compared to CNNs. However, the authors suggest that further pre-training could enhance performance, as ViT is scalable compared to other models. Additionally, scaling laws presented by Kaplan et al. for transformers in NLP suggest potential scalability to larger datasets in computer vision (CV). This hints at the possibility of transformers becoming a universal model capable of learning various human tasks and scaling with data. While this vision is not yet realized, the paper suggests a potential future trend in the field.
Summary
For more information
You can view more by clicking the link to the paper « An Image is Worth 16x16 Words: »
or simply clicking the picture