Transformer Architecture
1. General Introduction
a. Overview

The Transformer is a groundbreaking architecture in the field of natural language processing. In this context, we will explain the various aspects of this architecture.
Introduced in 2017 and first presented in the groundbreaking paper "Attention is All You Need" (Vaswani et al. 2017), the Transformer model has been a revolutionary contribution to deep learning and, some argue, to computing as a whole. Born as a tool for automatic neural machine translation, it has proven to be of much greater scope, extending its applicability beyond natural language processing (NLP) and solidifying its position as a versatile and generalized neural network architecture.
In this comprehensive guide, we will dissect the Transformer model down to its fundamental structure, exploring in detail each key component, from its attention mechanism to its encoder-decoder architecture. Not stopping at the fundamental level, we will traverse the landscape of large language models that harness the power of Transformers, examining their unique design attributes and functionalities. Expanding further horizons, we will explore the applications of Transformer models beyond NLP and delve into the current challenges and potential future directions of this influential architecture. Additionally, a curated list of open-source implementations and additional resources will be provided for those interested in further exploration.
Without frills or fanfare, let's dive in!

b. The purpose of Transformer networks
In order to understand how Transformer networks work, it's important to understand the concept of attention. When translating a sentence from one language to another, rather than looking at each word individually, you consider the sentence as a whole and the context in which it is used. Some words are given more importance as they help to better understand the sentence. This is what we call attention.

'
Consider another example. Imagine that you are watching a movie and trying to understand a particular scene. Instead of focusing on a single frame, you pay attention to the sequence of frames and the actions of the characters in order to understand the overall story. This approach helps you understand the context.
In Transformer networks, attention is used to assign different levels of importance to different parts of the input sequence, which helps the model better understand and generate a coherent output sequence.
The Transformer Network is powerful for tasks such as language understanding, due to its ability to capture long-range dependencies between elements that may be far apart from each other. This means that the relationships and dependencies between words in a sentence can be captured, even if they appear earlier or later in that sentence. This is important because the meaning of a word can depend on the words that appear before or after it.
c. The Transformer Architecture
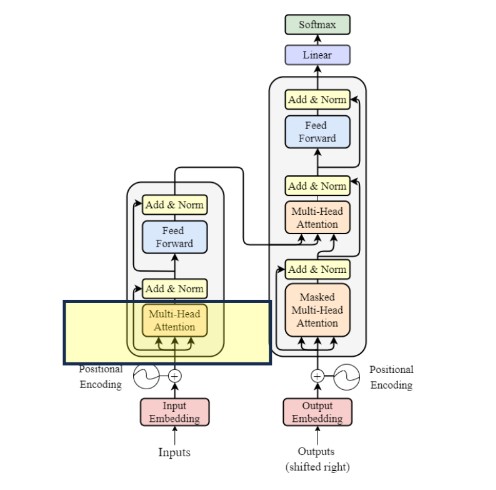
The Transformer architecture follows an encoder-decoder structure but does not rely on recurrence and convolutions in order to generate an output.
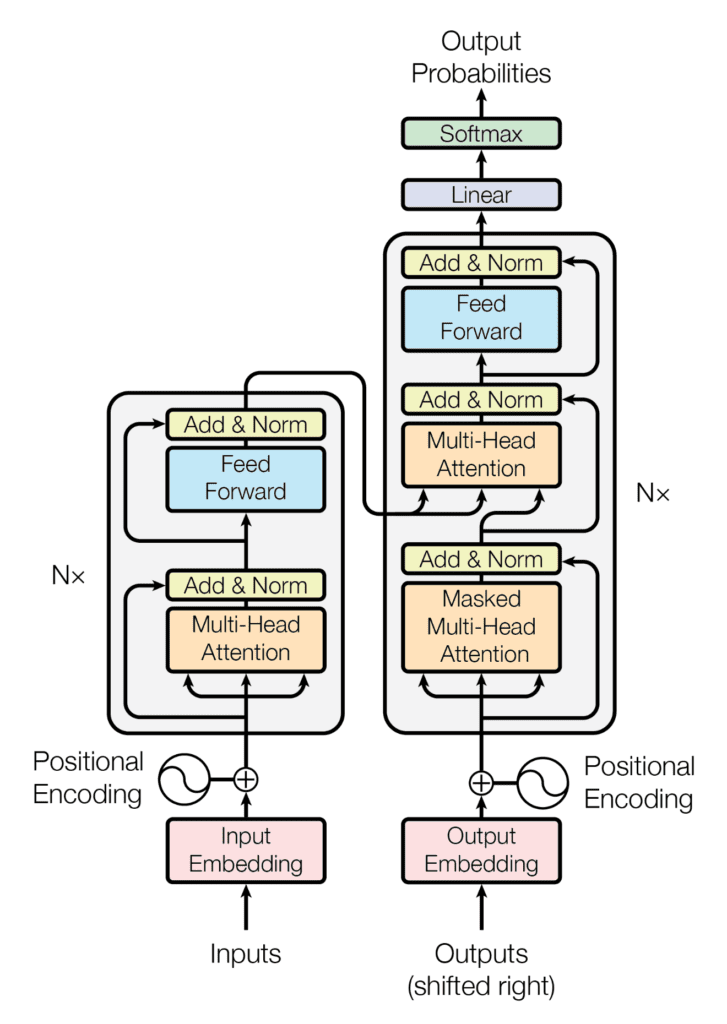
In a nutshell, the task of the encoder, on the left half of the Transformer architecture, is to map an input sequence to a sequence of continuous representations, which is then fed into a decoder.
The decoder, on the right half of the architecture, receives the output of the encoder together with the decoder output at the previous time step to generate an output sequence.
Note
At each step the model is auto-regressive, consuming the previously generated symbols as additional input when generating the next.
d. Key Components
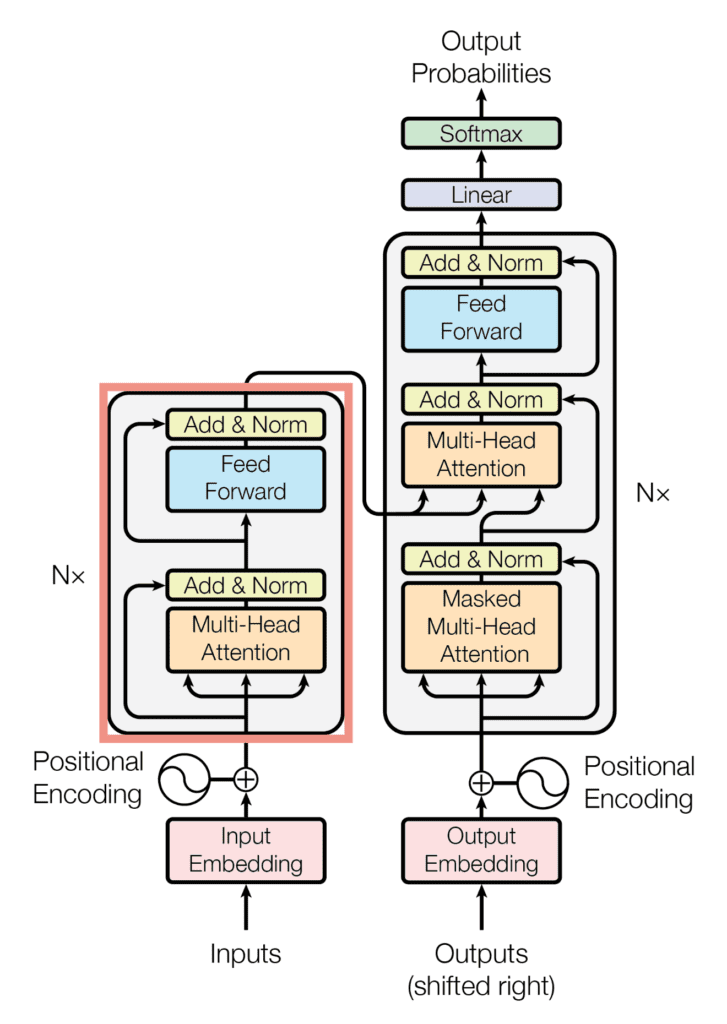
2. The Encoder
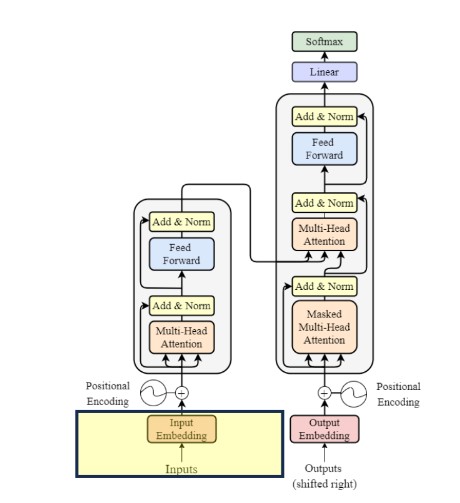
a. Tokenizer

Tokenization:
✓ Tokenization is the process of dividing a text into smaller units called "tokens."
✓ These tokens can be individual words, sub-words, or even individual characters, depending on the desired level of granularity.
✓ Each token is then converted into its corresponding numerical identifier from the model's vocabulary.
Vocabulary Building:
✓ To build the vocabulary, a set of the most common tokens in the language is typically selected.
✓ The vocabulary is limited to a certain number of tokens for performance and efficiency reasons, usually tens of thousands of tokens.
Token ID:
✓ Each token is associated with a unique identifier called a "Token ID."
✓ These Token IDs serve as numerical references for each token in the model's vocabulary.
Vocabulary Limitations:
✓ Due to the limitation of vocabulary size, some words may not be present in the model's vocabulary.
✓ In such cases, these words are usually split into sub-words or characters to represent them using the available tokens in the vocabulary.
Note
More details in Tokenization in Machine Learning Explained
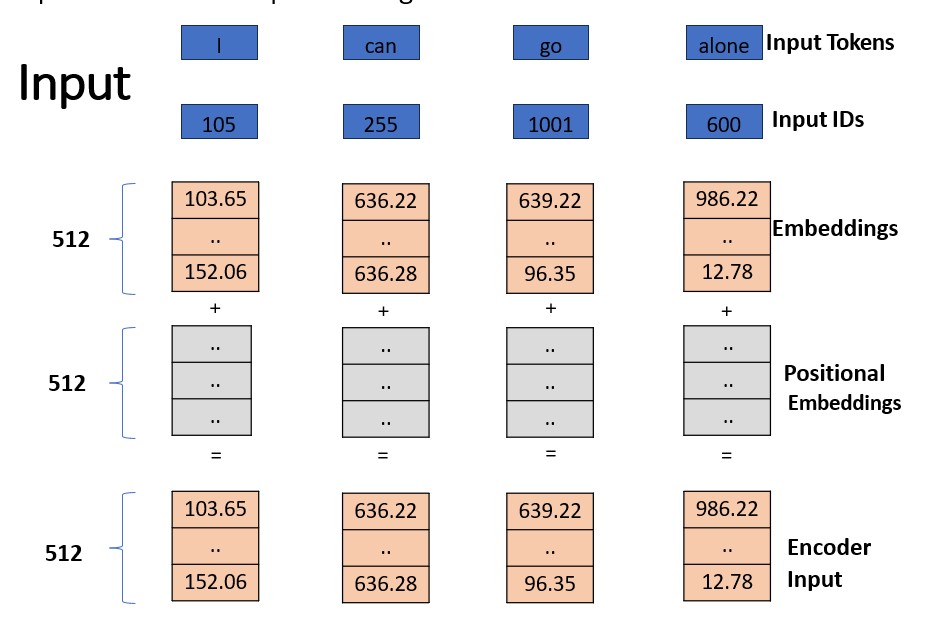
b. Input embedding
Refers to the initial step of converting the discrete tokens of an input sequence into continuous vector representations. This process is essential for the model to work with the input data in a suitable format.
Tokenization:

The input sequence, which could be a sequence of words, subwords, or characters, is first broken down into individual tokens. Each token typically represents a unit of meaning, like a word or a subword.
Embedding Representation:
Each token ID is associated with an embedding vector, where these vectors are initially randomly initialized. These vectors are of a fixed size, typically 512 dimensions.
Vector Representation:
These embedding vectors are arranged in columns, with each column representing a dimension of the embedding vector. This is different from the usual row-wise representation, where each row represents a token.
Random Initialization:
The values in the embedding vectors are initially set randomly. These values represent the initial state of the embeddings, and the Transformer model optimizes these values during training to better represent the semantics of the tokens.
To sum up, the process involves tokenizing the input sentence, looking up each token in the vocabulary to retrieve its ID, then using this ID to obtain the corresponding embedding vector. These embedding vectors are represented in a column-wise format, with each column representing a dimension of the embedding vector. Initially, these vectors are randomly initialized, and the Transformer model learns to optimize them during training.
Note
More details in Transformer Positional Embeddings and Encodings
c. Positional Encoding
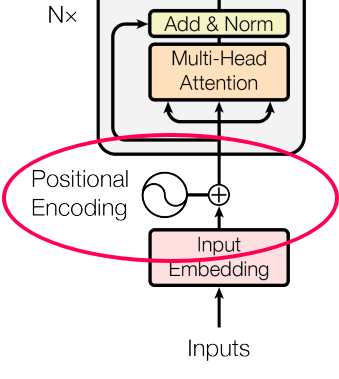
The significance of word position within a sentence is paramount. Depending on where a word is placed in a sentence, it can carry different meanings or implications. For instance, the word "not" might negate something if it appears in one part of the sentence, but it might have a different function elsewhere, such as merely continuing the speaker's thought without negating anything.
This variation in word meaning based on position emphasizes the importance of "position embedding." While word embeddings represent the meaning of a word, position embeddings represent the position of the word within the sentence. However, it's important to note that position embeddings are usually calculated only once and are not subject to training like word embeddings.
Mathematical Intuition
The idea behind positional encoding is to add a fixed-size vector to the embeddings of the input tokens, and this vector is determined based on the position of the token in the sequence. The positional encoding is designed in such a way that it reflects the position of a token in the sequence space, allowing the model to discern the order of tokens during processing.

- d: The dimension of the embedding vector. This is the length or number of components in each vector that represents a token or position in the input sequence.
- pos: The position of the token in the sequence. It represents the index or order of the token in the input sequence.
- i: he position along the dimension of the embedding vector. For each dimension i, there is a corresponding sine term (for even indices) and cosine term (for odd indices) in the formula.
Note
More details in Transformer Positional Embeddings and Encodings
d. self Attention

Note
self-attention (sometimes KQV-attention) layer is central mechanism in transformer architecture introduced in `Attention Is All You Need paper<https://arxiv.org/pdf/1706.03762.pdf>`__
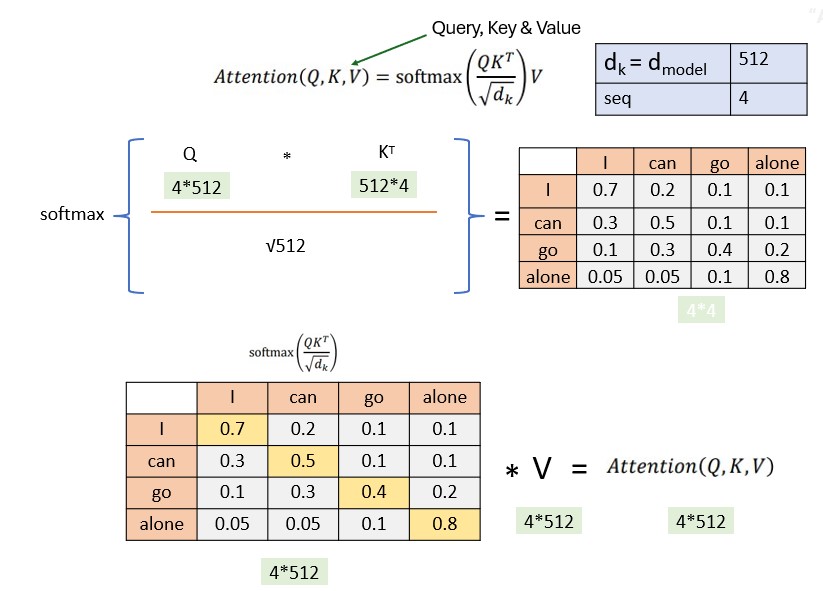
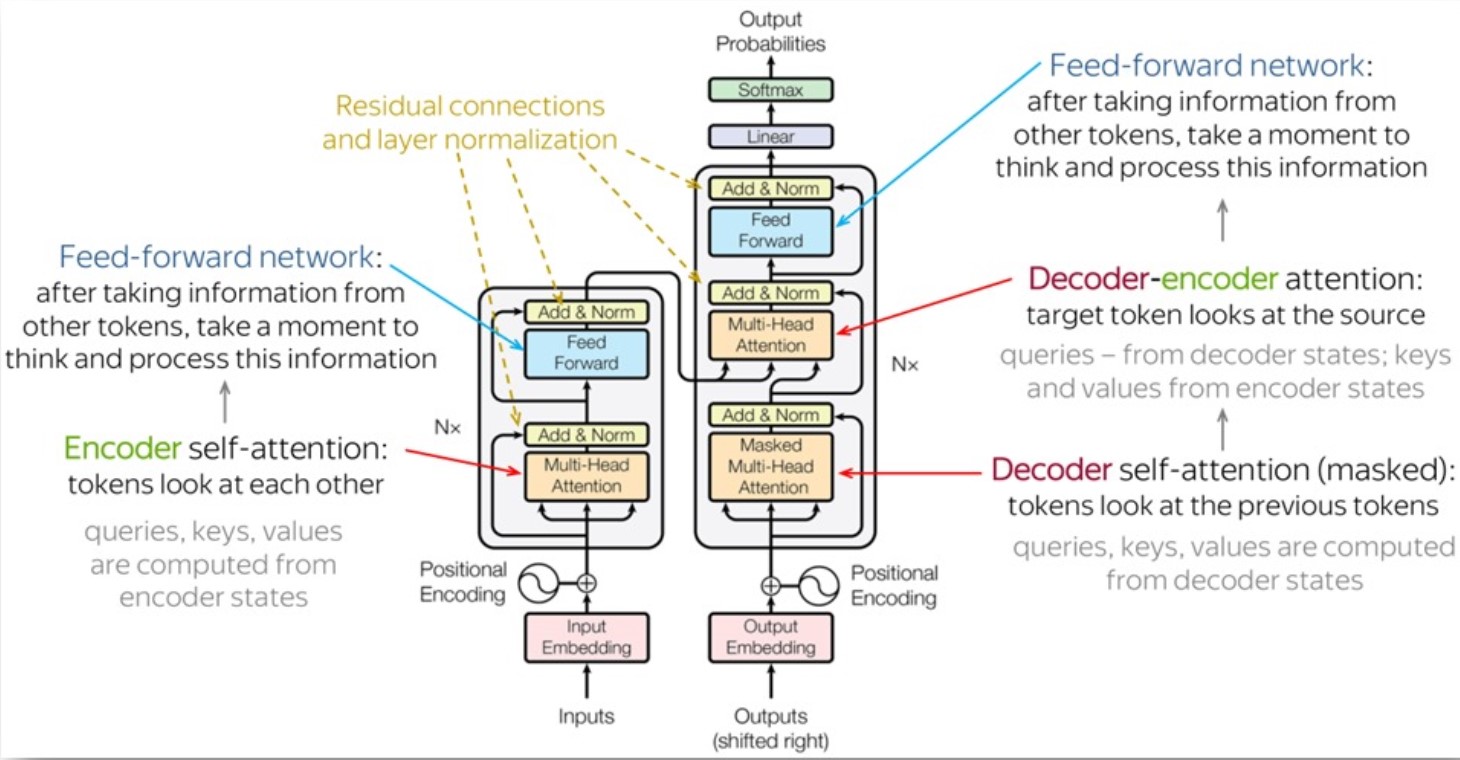
Self-Attention compares all input sequence members with each other, and modifies the corresponding output sequence positions. In other words, self-attention layer differentiably key-value searches the input sequence for each inputs, and adds results to the output sequence.
Key, Query, and Value:Each word in the input sequence is associated with three vectors: Key (K), Query (Q), and Value (V). These vectors are learned parameters for each word. Vectors are used to compute attention scores, determining how much focus should be given to other words in the sequence.
Attention Scores:For each word, the attention score with respect to other words is calculated by taking the dot product of the Query vector of the current word with the Key vectors of all other words. The scores are then scaled and passed through a softmax function to obtain a probability distribution, ensuring that the weights add up to 1.
Weighted Sum:The attention scores obtained for each word are used to calculate a weighted sum of the corresponding Value vectors. This weighted sum represents the importance of each word in the context of the current word, capturing the dependencies in the sequence.
Note
More details in paper Attention is all you need : dot-product is “scaled”, residual connection, layer normalization
e. Multi-Head Attention
✓ In multi-head attention, the attention mechanism is applied multiple times in parallel, with each instance referred to as a "head."
✓ For each head, three learnable linear projections (matrices) are applied to the input sequence to obtain separate projections for the query (Q), key (K), and value (V) vectors.
✓ The attention mechanism is then applied independently to each of these query, key, and value projections. The resulting outputs from all heads are concatenated and linearly transformed to produce the final multi-head attention output.
✓ The use of multiple heads allows the model to focus on different parts of the input sequence for different aspects or patterns, providing more flexibility and expressiveness.

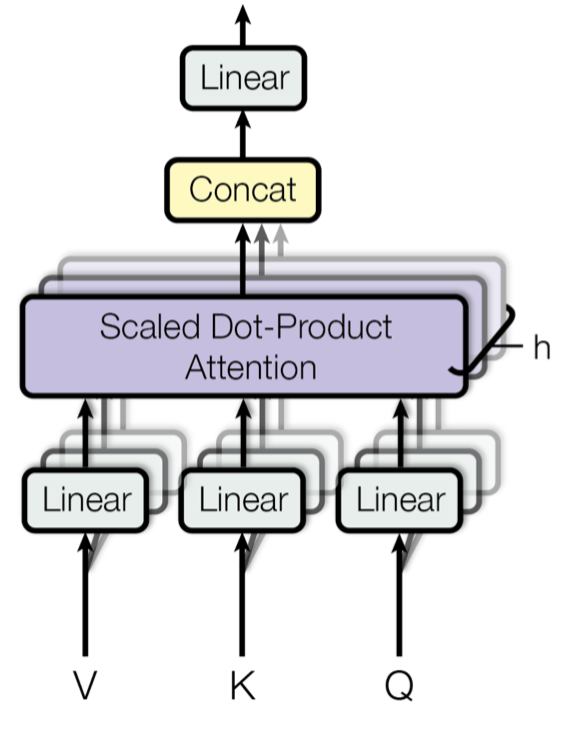

In practice, to enhance the capability of attention mechanisms to capture dependencies of various ranges within a sequence, a technique called multi-head attention is employed. Instead of a single attention pooling operation, multi-head attention utilizes independently learned linear projections for queries, keys, and values. These projected queries, keys, and values are then simultaneously processed through attention pooling in parallel. Subsequently, the outputs from each attention pooling operation, referred to as heads, are concatenated and transformed using another learned linear projection to generate the final output. Multi-head attention allows the model to combine knowledge from different behaviors of the attention mechanism, thereby improving its ability to capture dependencies across different ranges within a sequence. This approach is illustrated in Figure where fully connected layers are employed for learnable linear transformations.
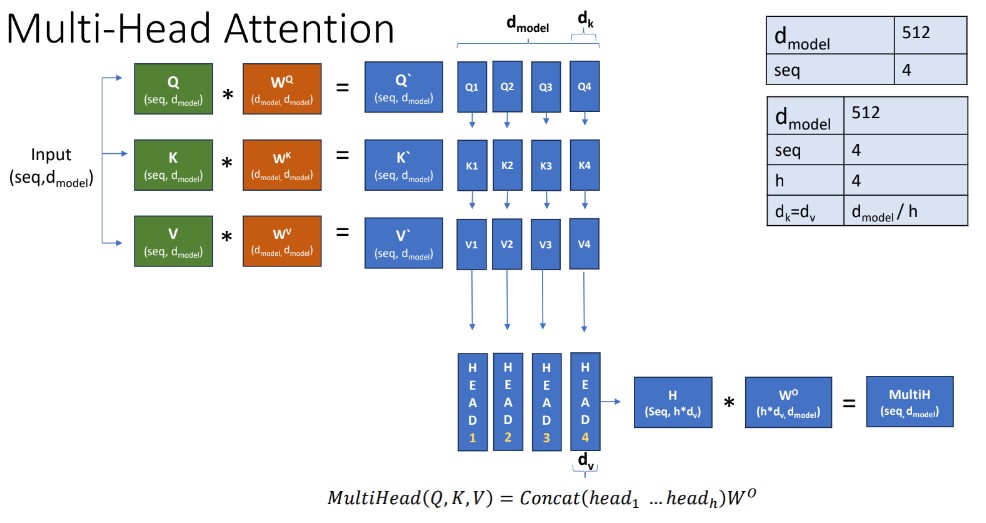
f. Add and norm - Norm
Following the addition operation, layer normalization is applied to normalize the combined result. Layer normalization normalizes the activations across the feature dimension (e.g., the dimension of the embedding vectors) for each position in the sequence.
The layer normalization operation is typically expressed as LayerNorm(Output)
where is a learnable normalization function.
This normalization step helps stabilize the training process by ensuring that the model's inputs and outputs have similar magnitudes, which can be beneficial for convergence and generalization.
g. Feed Forward
A specific type of neural network layer that is used within each encoder and decoder block. The feedforward layer is responsible for processing the information captured by the self-attention mechanism in the model.

The output from the self-attention mechanism-Add & Norm Sublayer
Linear TransformationInput is passed through a linear transformation
Activation FunctionApplication of a non-linear activation function, typically a rectified linear unit (ReLU). To introduces non-linearity to the model, allowing it to capture more complex patterns in the data.
Second Linear TransformationThe output from the activation function undergoes another linear transformation with a different weight matrix and bias term. This step further refines the information.
OutputThe final result is the output of the feedforward layer, and it is passed on to subsequent layers in the model.
Mathematical Intuition
Mathematically, if X represents the input, the feedforward layer can be expressed as:
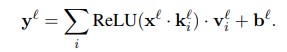
W1, b1 : the weights and bias for the first linear transformation.
W2, b2 : the weights and bias for the second linear transformation.
ReLU : the rectified linear unit activation function.
Note
The feedforward layer plays a crucial role in capturing complex patterns and relationships in the input data, allowing the model to learn and represent hierarchical features effectively.
h. Residual Connections
Another point is that the encoder block uses residual connections, which is simply an element-wise addition:
Note
Sublayer is either multi-head attention or point-wise feed-forward network.

Residual connections carry over the previous embeddings to the subsequent layers. As such, the encoder blocks enrich the embedding vectors with additional information obtained from the multi-head self-attention calculations and position-wise feed-forward networks.
i. Conclusion
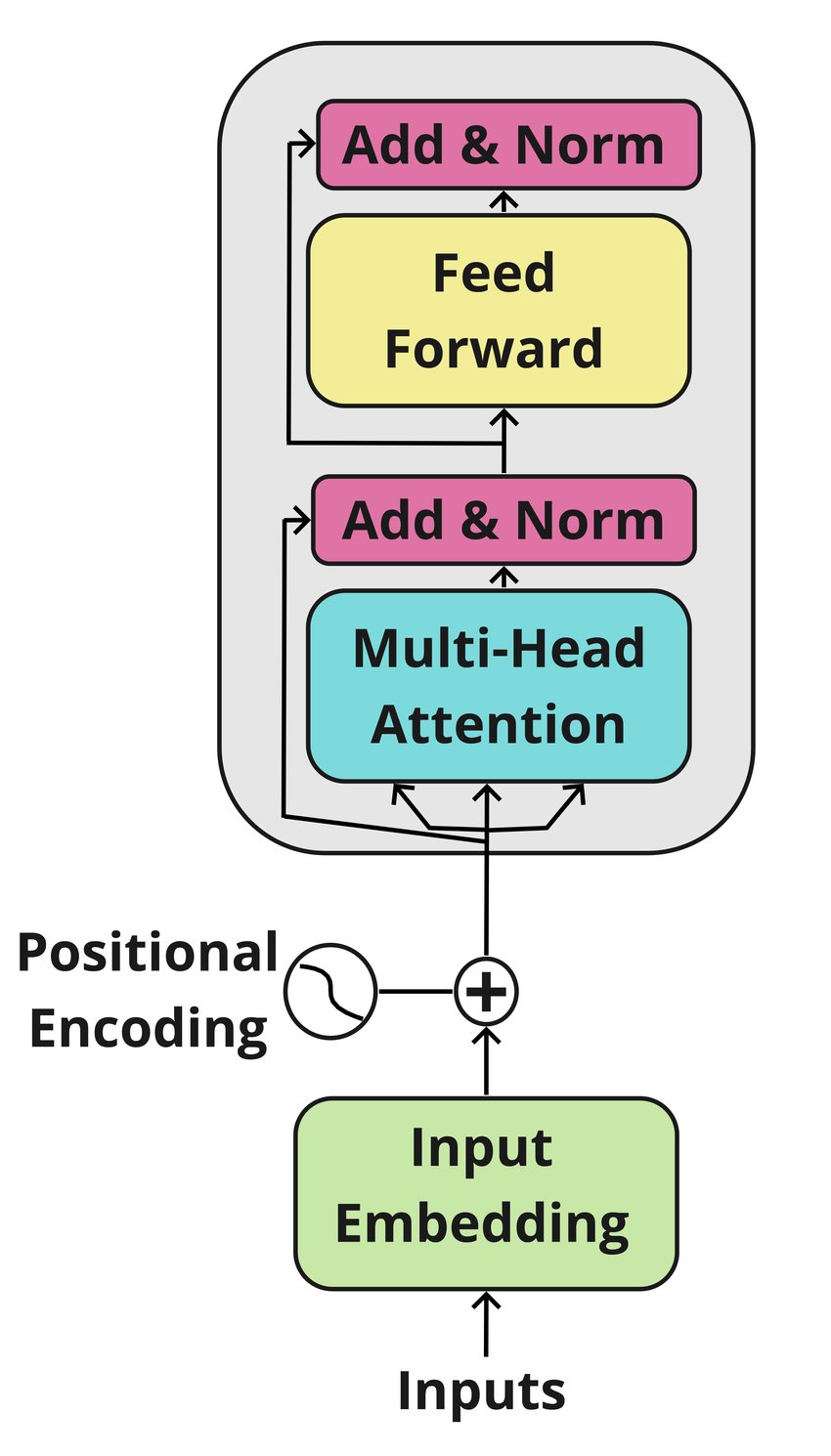
The document provides a detailed overview of the Transformer model encoder and the different stages and mechanisms used in data processing.
First, the tokenization process is explained, which involves dividing a text into smaller units called "tokens". These tokens are then converted into numerical identifiers that correspond to the model's vocabulary.
Next, input embedding is described, where tokens are converted into continuous vectors for processing by the model. These vectors are randomly initialized and optimized during training to better represent the meaning of the tokens.
Positional encoding is discussed to account for the order of tokens in the sequence, which is crucial for capturing dependencies between words.
The self-attention mechanism is introduced as a method for calculating attention weights between tokens, allowing the model to focus on different parts of the sequence depending on the context.
Next, multi-head attention is explained, which is an extension of self-attention that allows the model to combine knowledge from different attention heads to capture dependencies across different ranges within a sequence.
The addition and normalization layer, as well as the feed-forward layer are discussed to improve stability and the model's ability to learn complex hierarchical representations.
Finally, residual connections are introduced to facilitate the flow of information through the encoder's layers.
In conclusion, the document provides a comprehensive understanding of the internal workings of the Transformer encoder and highlights the importance of the various stages and mechanisms in effective data processing.
Note
You can view more by clicking the « Transformer’s Encoder »
j. BIBLIOGRAPHIC
For more information
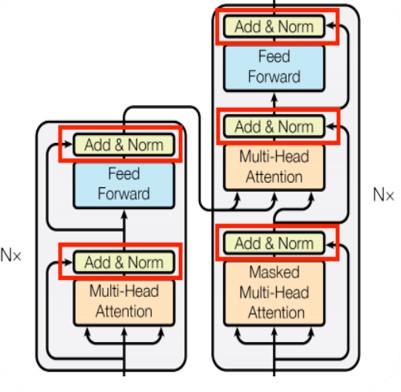
3. The Decoder
Note
The decoder block is similar to the encoder block, except it calculates the source-target attention.
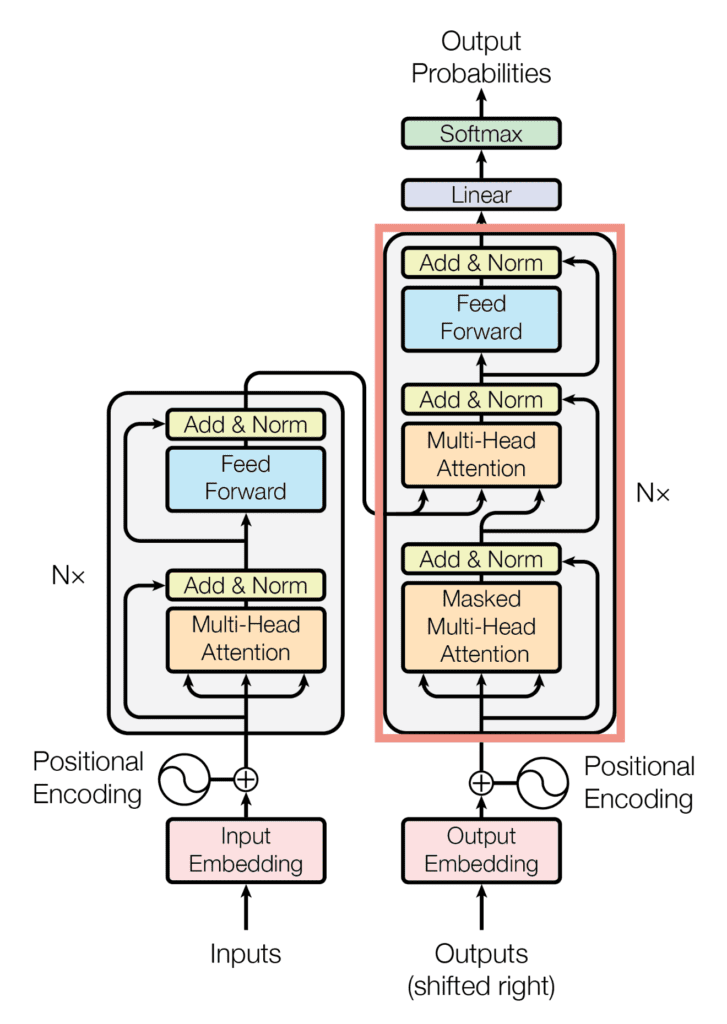
Overview
A transformer decoder is a neural network architecture used in natural language processing tasks such as machine translation and text generation. It combines with an encoder to process input text and generate output text. It has multiple layers of self-attention and feed-forward neural networks. It is trained using a combination of supervised and unsupervised learning techniques. It is known for its accuracy and natural-sounding output.
a. Introduction
The transformer decoder is a crucial component of the Transformer architecture, which has revolutionized the field of natural language processing (NLP) in recent years. It is known for its state-of-the-art performance on various tasks, including machine translation, language modeling, and summarization. The transformer decoder works in conjunction with the encoder, which processes the input sequence and generates a sequence of contextualized representations known as "hidden states." These hidden states capture the meaning and context of the input sequence and are passed on to the transformer decoder.
The transformer decoder block comprises multiple layers of self-attention and feed-forward neural networks, which work together to process the input and generate the output. The transformer decoder then uses these hidden states and the previously generated output tokens to predict the next output token and generate the final output sequence. This encoder-decoder architecture is necessary for NLP tasks as it allows for more accurate and natural-sounding output.
As mentioned before, an input to the decoder is an output shifted right, which becomes a sequence of embeddings with positional encoding. So, we can think of the decoder block as another encoder generating enriched embeddings useful for translation outputs.

Note
The decoder and encoder share several similarities, but they differ in their input. We will explain this difference in the next section.
b. difference between decoder and encoder
The first sublayer receives the previous output of the decoder stack, augments it with positional information, and implements multi-head self-attention over it. While the encoder is designed to attend to all words in the input sequence regardless of their position in the sequence, the decoder is modified to attend only to the preceding words. Hence, the prediction for a word at position i can only depend on the known outputs for the words that come before it in the sequence. In the multi-head attention mechanism (which implements multiple, single attention functions in parallel), this is achieved by introducing a mask over the values produced by the scaled multiplication of matrices Q and K . This masking is implemented by suppressing the matrix values that would otherwise correspond to illegal connections:

c. Masked multi-head attention
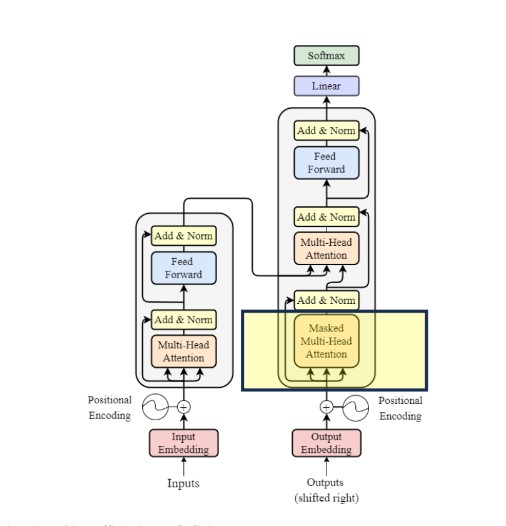
means the multi-head attention receives inputs with masks so that the attention mechanism does not use information from the hidden (masked) positions. The paper mentions that they used the mask inside the attention calculation by setting attention scores to negative infinity (or a very large negative number). The softmax within the attention mechanisms effectively assigns zero probability to masked positions.
Intuitively, it is as if we were gradually increasing the visibility of input sentences by the masks:


Note
Causal Model: The model must not be able to see the future words
d. Multi-Head Attention
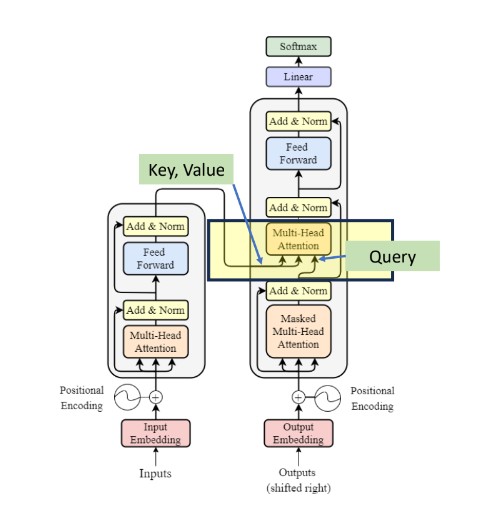
The second layer implements a multi-head self-attention mechanism similar to the one implemented in the first sublayer of the encoder. On the decoder side, this multi-head mechanism receives the queries from the previous decoder sublayer and the keys and values from the output of the encoder. This allows the decoder to attend to all the words in the input sequence.
The source-target attention is another multi-head attention that calculates the attention values between the features (embeddings) from the input sentence and the features from the output (yet partial) sentence.
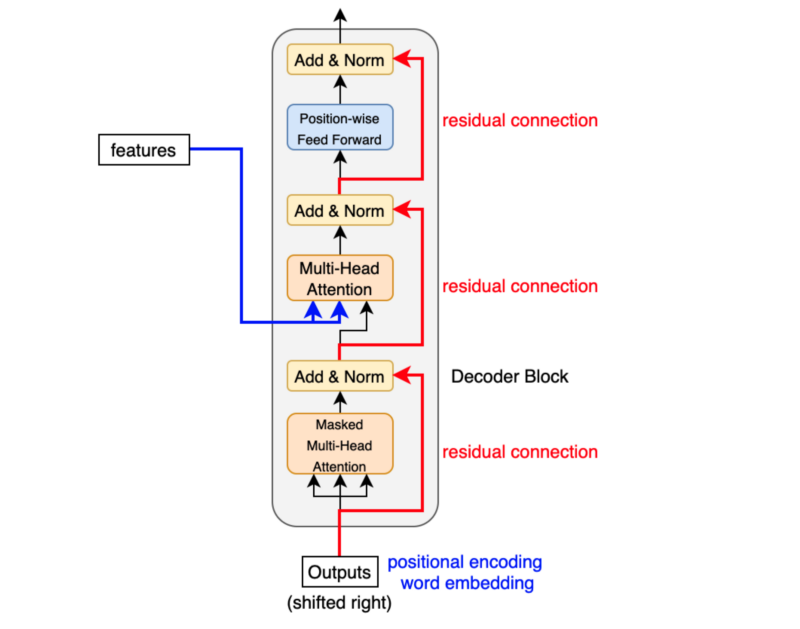
e. Feed Forward
The third layer implements a fully connected feed-forward network, similar to the one implemented in the second sublayer of the encoder.
Note
urthermore, the three sublayers on the decoder side also have residual connections around them and are succeeded by a normalization layer.
Positional encodings are also added to the input embeddings of the decoder in the same manner as previously explained for the encoder.
f. Conclusion
The transformer architecture assumes no recurrence or convolution pattern when processing input data. As such, the transformer architecture is suitable for any sequence data. As long as we can express our input as sequence data, we can apply the same approach, including computer vision (sequences of image patches) and reinforcement learning (sequences of states, actions, and rewards).
In the case of the original transformer, the mission is to translate, and it uses the architecture to learn to enrich embedding vectors with relevant information for translation.

For more information
3. Softmax in Transformers

In transformers, the softmax function is commonly used as part of the mechanism for calculating attention scores, which are critical for the self-attention mechanism that forms the basis of the model. It is essential for several reasons:

- Attention Weights: Transformers use attention mechanisms to weigh the importance of different input tokens when generating an output. Softmax is used to convert the raw attention scores, often called “logits,” into a probability distribution over the input tokens. This distribution assigns higher attention weights to more relevant tokens and lower weights to less relevant ones.
- Probability Distribution: Softmax ensures that the attention scores are transformed into a valid probability distribution, with all values between 0 and 1 and the sum equal to 1. This property is important for correctly weighing the input tokens while taking into account their relative importance.
- Stabilizing Gradients:The softmax function has a smooth gradient, which makes it easier to train deep neural networks like transformers using techniques like backpropagation. It helps with gradient stability during training, making it easier for the model to learn and adjust its parameters.
The softmax function is typically applied to the raw attention scores obtained from the dot product of query and key vectors in the self-attention mechanism. The formula for computing the softmax attention weights for a given query token in a transformer is as follows:
Here, Q represents the query vector, K represents the key vectors of the input tokens, and the exponential function (\exp) is used to transform the raw scores into positive values. The denominator ensures that the resulting values form a probability distribution.
In summary, the softmax function is a crucial component of transformers that enables them to learn how to weigh input tokens based on their relevance to the current context, making the model’s self-attention mechanism effective in capturing dependencies and relationships in the data.
And the most important thing is the softmax is used to prevent exploding gradient or vanishing gradient problems.
For more information