Transformer: Attention Is All You Need
"Attention Is All You Need" is a research paper by Ashish Vaswani et al. that introduces the Transformer model, a neural network architecture for sequence-to-sequence tasks. The paper challenges the conventional use of recurrence and convolution in such tasks and advocates for self-attention mechanisms instead.

1. Introduction
The paper begins by discussing the limitations of traditional sequence-to-sequence models, which rely on recurrence and convolution. It highlights the need for better handling of long-range dependencies and contextual understanding in tasks like machine translation and text summarization.
2. Background
An overview of sequence-to-sequence tasks and existing approaches is provided. The limitations of traditional methods, such as dependence on recurrence and convolution, are discussed.
3. Self-Attention Mechanism
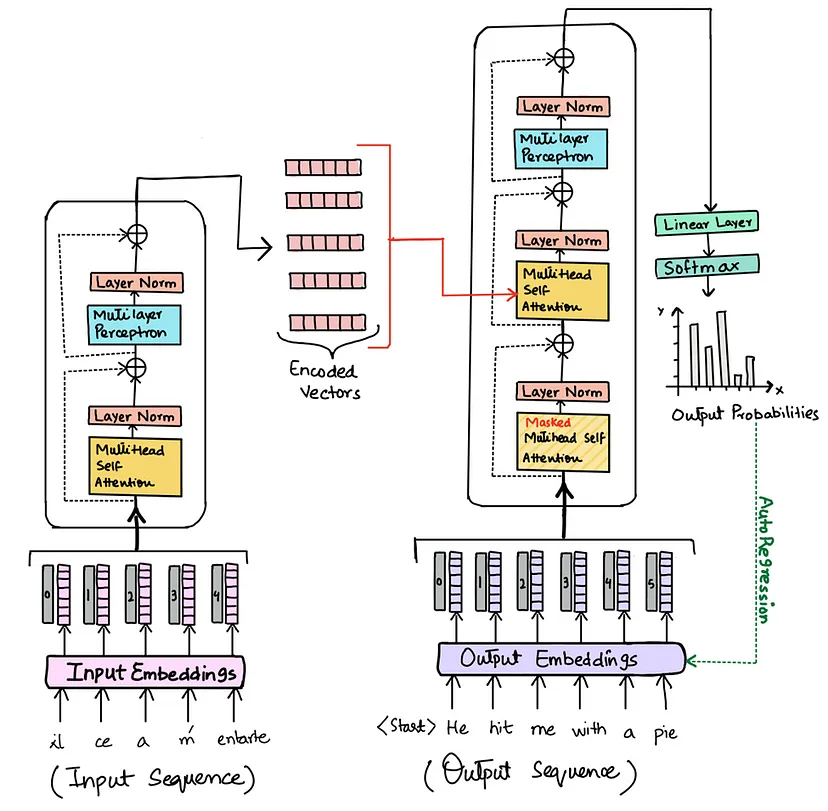
The self-attention mechanism is introduced as an alternative approach to processing sequential data. It allows the model to focus on all positions in the input sequence simultaneously, capturing long-range dependencies and contextual information effectively.
4. Multi-Head Self-Attention
The paper proposes multi-head self-attention, a variant of the self-attention mechanism. This technique computes multiple attention weights in parallel, capturing different relationships between input elements.
5. Position-Wise Feed-Forward Networks
Position-wise feed-forward networks (FFNs) are introduced to process the output of the attention mechanism. FFNs transform the output into a higher dimensional space, enhancing the model's representation capabilities.
6. Transformer Model
The Transformer model is proposed, comprising an encoder and a decoder, each composed of multiple identical layers. Each layer contains two sub-layers: multi-head self-attention and position-wise FFNs.
7. Attention Visualization
Visualizations of attention weights generated by the Transformer model are provided. These demonstrate the model's ability to capture linguistic structures and relationships.
8. Experimental Results
The Transformer model is evaluated on various machine translation tasks and compared to traditional RNN and CNN models. It outperforms these models, achieving state-of-the-art results in many cases.
9. Conclusion
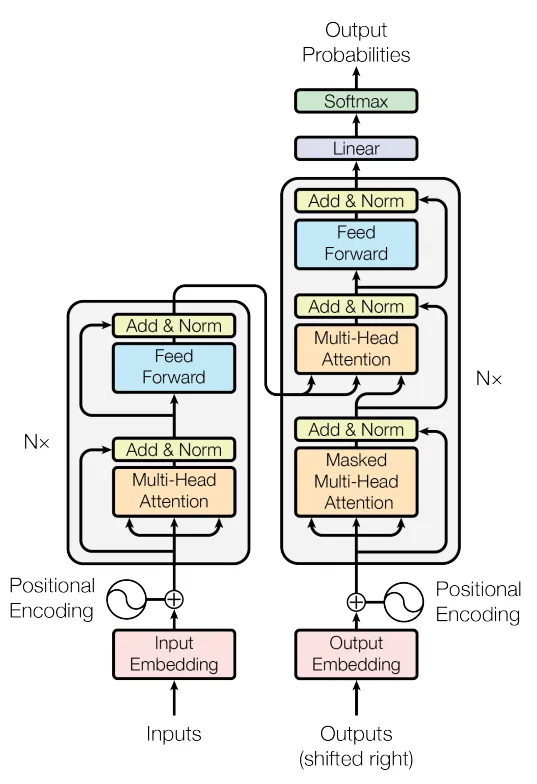
The paper concludes that attention mechanisms alone are sufficient for sequence-to-sequence tasks, without the need for recurrence or convolution. The Transformer model is highlighted as more parallelizable and efficient for large-scale tasks.
Summary
The paper presents the Transformer model as a novel approach to sequence-to-sequence tasks, achieving impressive results without using recurrence or convolution. It demonstrates the effectiveness of attention mechanisms in capturing complex relationships in sequential data.
For more information
You can view more by clicking the link to the paper « Attention is all you need »
or simply clicking the picture
